分布式锁-redission
分布式锁-redission
# 分布式锁-redission功能介绍
基于setnx实现的分布式锁存在下面的问题:
重入问题:重入问题是指 获得锁的线程可以再次进入到相同的锁的代码块中,可重入锁的意义在于防止死锁,比如HashTable这样的代码中,他的方法都是使用synchronized修饰的,假如他在一个方法内,调用另一个方法,那么此时如果是不可重入的,不就死锁了吗?所以可重入锁他的主要意义是防止死锁,我们的synchronized和Lock锁都是可重入的。
不可重试:是指目前的分布式只能尝试一次,我们认为合理的情况是:当线程在获得锁失败后,他应该能再次尝试获得锁。
**超时释放:**我们在加锁时增加了过期时间,这样的我们可以防止死锁,但是如果卡顿的时间超长,虽然我们采用了lua表达式防止删锁的时候,误删别人的锁,但是毕竟没有锁住,有安全隐患
主从一致性: 如果Redis提供了主从集群,当我们向集群写数据时,主机需要异步的将数据同步给从机,而万一在同步过去之前,主机宕机了,就会出现死锁问题。

那么什么是Redission呢
Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
Redission提供了分布式锁的多种多样的功能

# 分布式锁-Redission快速入门
引入依赖:
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
2
3
4
5
配置Redisson客户端:
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.150.101:6379")
.setPassword("123321");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
如何使用Redission的分布式锁
@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{
//获取锁(可重入),指定锁的名称
RLock lock = redissonClient.getLock("anyLock");
//尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
boolean isLock = lock.tryLock(1,10,TimeUnit.SECONDS);
//判断获取锁成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
在 VoucherOrderServiceImpl
注入RedissonClient
@Resource
private RedissonClient redissonClient;
@Override
public Result seckillVoucher(Long voucherId) {
// 1.查询优惠券
SeckillVoucher voucher = seckillVoucherService.getById(voucherId);
// 2.判断秒杀是否开始
if (voucher.getBeginTime().isAfter(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀尚未开始!");
}
// 3.判断秒杀是否已经结束
if (voucher.getEndTime().isBefore(LocalDateTime.now())) {
// 尚未开始
return Result.fail("秒杀已经结束!");
}
// 4.判断库存是否充足
if (voucher.getStock() < 1) {
// 库存不足
return Result.fail("库存不足!");
}
Long userId = UserHolder.getUser().getId();
//创建锁对象 这个代码不用了,因为我们现在要使用分布式锁
//SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);
RLock lock = redissonClient.getLock("lock:order:" + userId);
//获取锁对象
boolean isLock = lock.tryLock();
//加锁失败
if (!isLock) {
return Result.fail("不允许重复下单");
}
try {
//获取代理对象(事务)
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
} finally {
//释放锁
lock.unlock();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 分布式锁-redission可重入锁原理
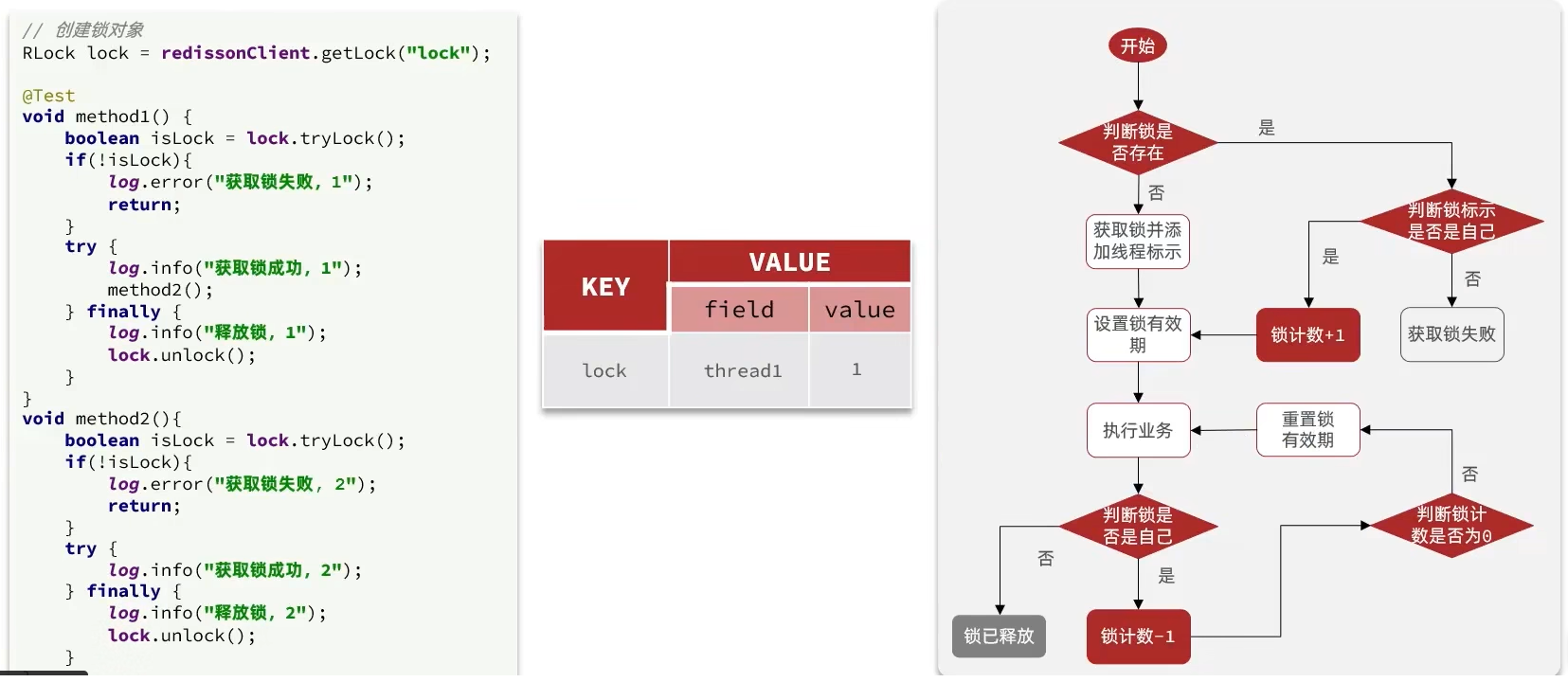
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
在redission中,我们的也支持支持可重入锁
在分布式锁中,他采用hash结构用来存储锁,其中大key表示表示这把锁是否存在,用小key表示当前这把锁被哪个线程持有,所以接下来我们一起分析一下当前的这个lua表达式
这个地方一共有3个参数
KEYS[1] : 锁名称
ARGV[1]: 锁失效时间
ARGV[2]: id + ":" + threadId; 锁的小key
exists: 判断数据是否存在 name:是lock是否存在,如果==0,就表示当前这把锁不存在
redis.call('hset', KEYS[1], ARGV[2], 1);此时他就开始往redis里边去写数据 ,写成一个hash结构
Lock{
id + ":" + threadId : 1
}
如果当前这把锁存在,则第一个条件不满足,再判断
redis.call('hexists', KEYS[1], ARGV[2]) == 1
此时需要通过大key+小key判断当前这把锁是否是属于自己的,如果是自己的,则进行
redis.call('hincrby', KEYS[1], ARGV[2], 1)
将当前这个锁的value进行+1 ,redis.call('pexpire', KEYS[1], ARGV[1]); 然后再对其设置过期时间,如果以上两个条件都不满足,则表示当前这把锁抢锁失败,最后返回pttl,即为当前这把锁的失效时间
如果小伙帮们看了前边的源码, 你会发现他会去判断当前这个方法的返回值是否为null,如果是null,则对应则前两个if对应的条件,退出抢锁逻辑,如果返回的不是null,即走了第三个分支,在源码处会进行while(true)的自旋抢锁。
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);"
2
3
4
5
6
7
8
9
10
11
# 分布式锁-redission锁重试和WatchDog机制
说明:由于课程中已经说明了有关tryLock的源码解析以及其看门狗原理,所以笔者在这里给大家分析lock()方法的源码解析,希望大家在学习过程中,能够掌握更多的知识
抢锁过程中,获得当前线程,通过tryAcquire进行抢锁,该抢锁逻辑和之前逻辑相同
1、先判断当前这把锁是否存在,如果不存在,插入一把锁,返回null
2、判断当前这把锁是否是属于当前线程,如果是,则返回null
所以如果返回是null,则代表着当前这哥们已经抢锁完毕,或者可重入完毕,但是如果以上两个条件都不满足,则进入到第三个条件,返回的是锁的失效时间,同学们可以自行往下翻一点点,你能发现有个while( true) 再次进行tryAcquire进行抢锁
long threadId = Thread.currentThread().getId();
Long ttl = tryAcquire(-1, leaseTime, unit, threadId);
// lock acquired
if (ttl == null) {
return;
}
2
3
4
5
6
接下来会有一个条件分支,因为lock方法有重载方法,一个是带参数,一个是不带参数,如果带带参数传入的值是-1,如果传入参数,则leaseTime是他本身,所以如果传入了参数,此时leaseTime != -1 则会进去抢锁,抢锁的逻辑就是之前说的那三个逻辑
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
2
3
如果是没有传入时间,则此时也会进行抢锁, 而且抢锁时间是默认看门狗时间 commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout()
ttlRemainingFuture.onComplete((ttlRemaining, e) 这句话相当于对以上抢锁进行了监听,也就是说当上边抢锁完毕后,此方法会被调用,具体调用的逻辑就是去后台开启一个线程,进行续约逻辑,也就是看门狗线程
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(waitTime,
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
if (e != null) {
return;
}
// lock acquired
if (ttlRemaining == null) {
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
2
3
4
5
6
7
8
9
10
11
12
13
14
此逻辑就是续约逻辑,注意看commandExecutor.getConnectionManager().newTimeout() 此方法
Method( new TimerTask() {},参数2 ,参数3 )
指的是:通过参数2,参数3 去描述什么时候去做参数1的事情,现在的情况是:10s之后去做参数一的事情
因为锁的失效时间是30s,当10s之后,此时这个timeTask 就触发了,他就去进行续约,把当前这把锁续约成30s,如果操作成功,那么此时就会递归调用自己,再重新设置一个timeTask(),于是再过10s后又再设置一个timerTask,完成不停的续约
那么大家可以想一想,假设我们的线程出现了宕机他还会续约吗?当然不会,因为没有人再去调用renewExpiration这个方法,所以等到时间之后自然就释放了。
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) {
// reschedule itself
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 分布式锁-redission锁的MutiLock原理
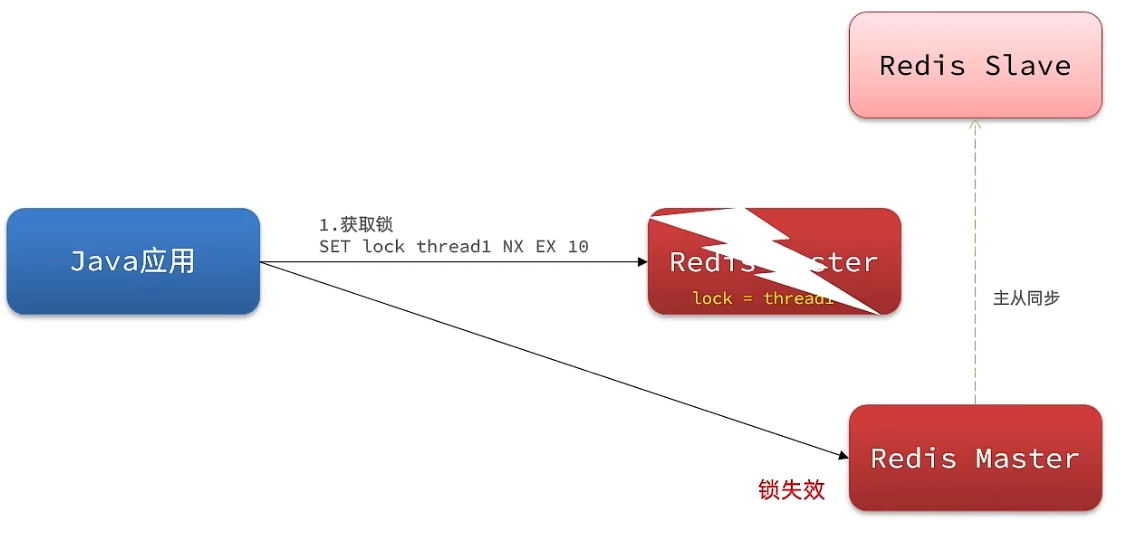
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。
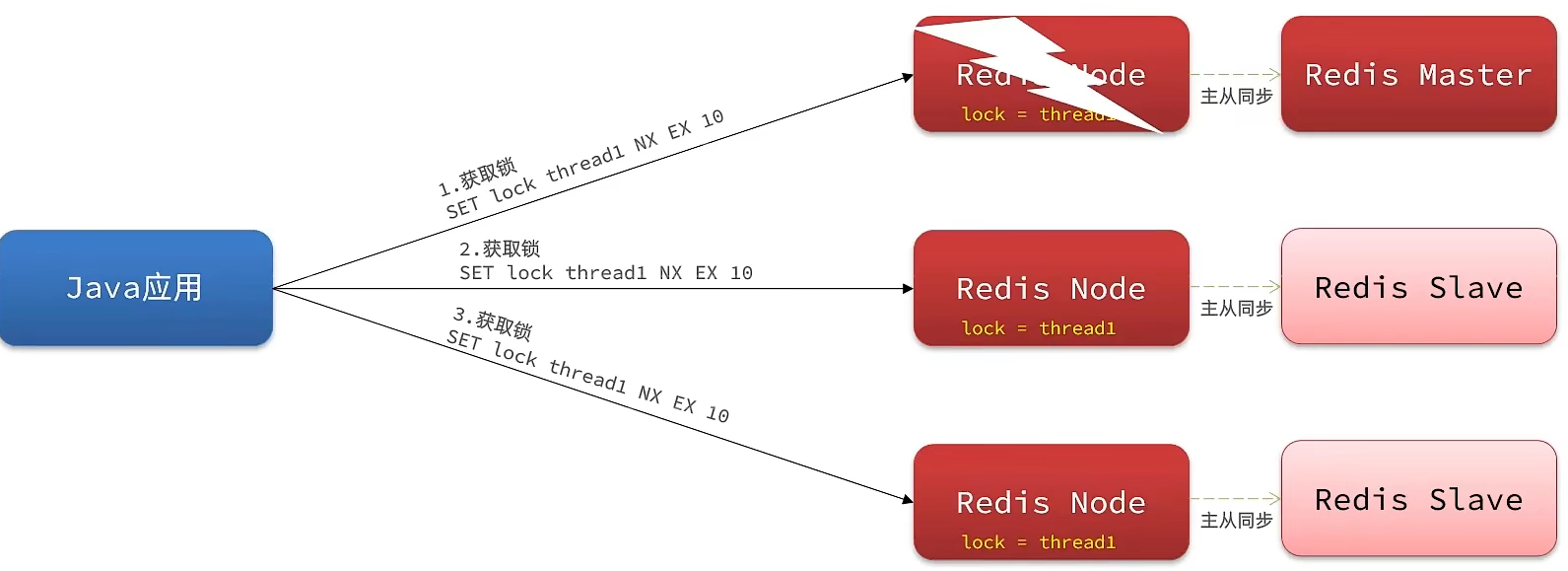
为了解决这个问题,redission提出来了MutiLock锁,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。
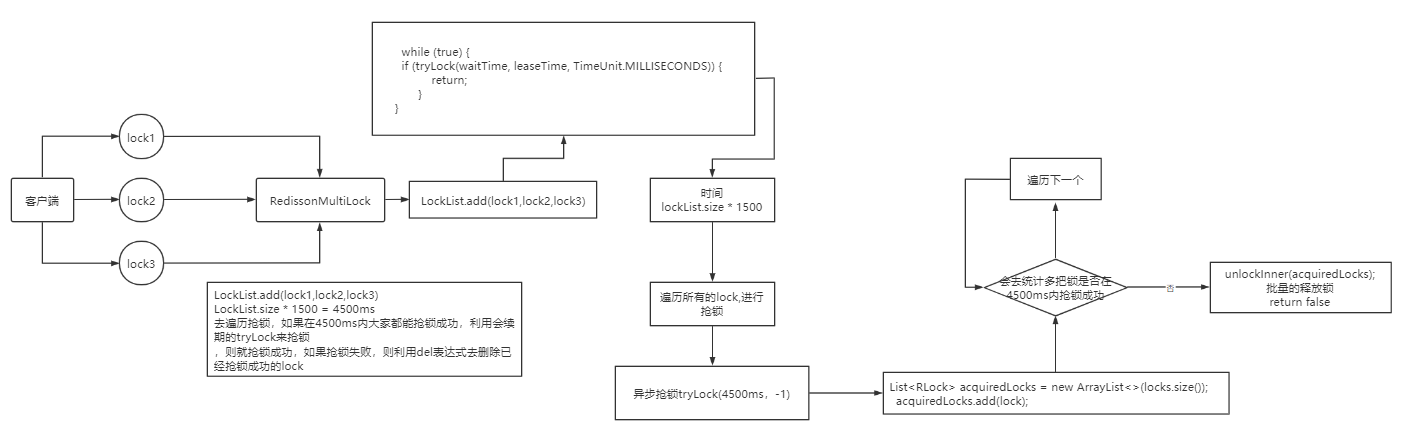
那么MutiLock 加锁原理是什么呢?笔者画了一幅图来说明
当我们去设置了多个锁时,redission会将多个锁添加到一个集合中,然后用while循环去不停去尝试拿锁,但是会有一个总共的加锁时间,这个时间是用需要加锁的个数 * 1500ms ,假设有3个锁,那么时间就是4500ms,假设在这4500ms内,所有的锁都加锁成功, 那么此时才算是加锁成功,如果在4500ms有线程加锁失败,则会再次去进行重试.