 Prometheus介绍
Prometheus介绍
老牌监控能干的它都能干,它能干的老牌监控不一定能干;与云原生容器技术十分契合
# Prometheus工作流程
- Prometheus server可定期从活跃的(up)目标主机上(target)拉取监控指标数据,目标主机的监控数据可通过配置静态job或者服务发现的方式被prometheus server采集到,这种方式默认的pull方式拉取指标;也可通过pushgateway把采集的数据上报到prometheus server中;还可通过一些组件自带的exporter采集相应组件的数据;
- Prometheus server把采集到的监控指标数据保存到本地磁盘或者数据库;
- Prometheus采集的监控指标数据按时间序列存储,通过配置报警规则,把触发的报警发送到alertmanager
- Alertmanager通过配置报警接收方,发送报警到邮件,微信或者钉钉等
- Prometheus 自带的web ui界面提供PromQL查询语言,可查询监控数据
- Grafana可接入prometheus数据源,把监控数据以图形化形式展示出
# Prometheus组件介绍
1)Prometheus Server: 用于收集和存储时间序列数据。
2)Client Library: 客户端库,检测应用程序代码,当Prometheus抓取实例的HTTP端点时,客户端库会将所有跟踪的metrics指标的当前状态发送到prometheus server端。
3)Exporters: prometheus支持多种exporter,通过exporter可以采集metrics数据,然后发送到prometheus server端,所有向promtheus server提供监控数据的程序都可以被称为exporter
4)Alertmanager: 从 Prometheus server 端接收到 alerts 后,会进行去重,分组,并路由到相应的接收方,发出报警,常见的接收方式有:电子邮件,微信,钉钉, slack等。
5)Grafana:监控仪表盘,可视化监控数据
6)pushgateway: 各个目标主机可上报数据到pushgateway,然后prometheus server统一从pushgateway拉取数据。
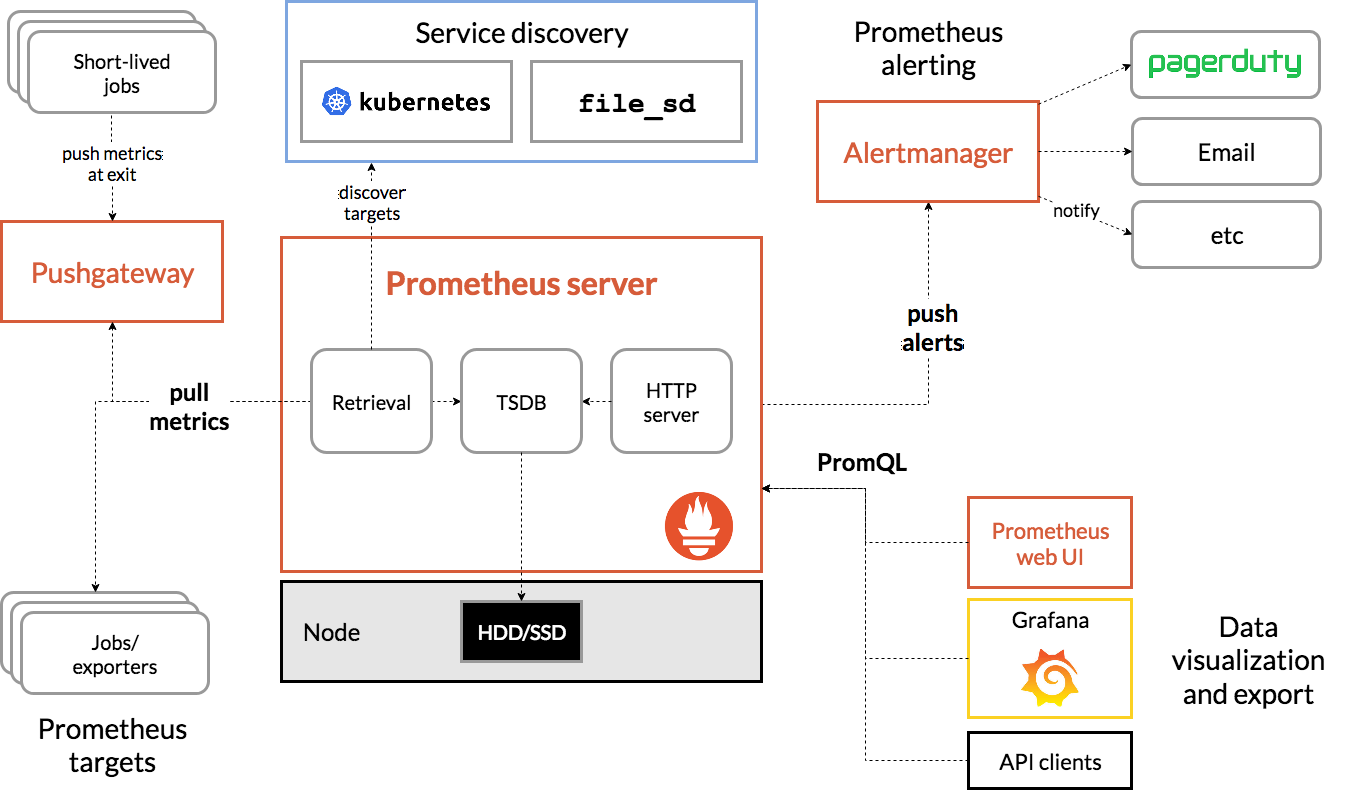
从上图可发现,Prometheus整个生态圈组成主要包括prometheus server,Exporter,pushgateway,alertmanager,grafana,Web ui界面
Prometheus server由三个部分组成,Retrieval,Storage,PromQL
- Retrieval负责在活跃的target主机上抓取监控指标数据
- Storage存储主要是把采集到的数据存储到磁盘中
- PromQL是Prometheus提供的查询语言模块。
下面是组件详细介绍
# job/exporter
Job/Exporter属于Prometheus target,是Prometheus监控的对 象
Job分为两种:
- 长时间执行:可以使用Prometheus Client集成进行监控;
- 短时间执行:可以将监控数据推送到Pushgateway中缓存。
# pushgateway
Prometheus是拉模式为主的监控系统,它的推模式就是通过 Pushgateway组件实现的。Pushgateway是支持临时性Job主动推送指标 的中间网关,它本质上是一种用于监控Prometheus服务器无法抓取的 资源的解决方案。
被监控的数据推送过程: 被采集监控指标的应用程序->pushgateway->prometheus server
使用场景:
- 临时/短作业
- 批处理作业
自身问题:存在单点故障问题,宕机后将失去所有来源的监控
优点:不会自动删除任何指标数据,因此必须使用pushgateway的api从推送网关中删除过期的指标。
curl -X DELETE http://pushgateway.example.org:9091/metrics/job/some_job/instance/some_instance
# 配置告警
前面提到的alertmanager.yml配置文件默认是不存在的,需要新
建。这个文件主要是设置告警方式的,比如邮件、钉钉(webhook)、
微信、pagerduty等方式。
它的选项主要有 email_config、
hipchat_config、pagerduty_config、pushover_config、
slack_config、opsgenie_config、victorops_config等。
docker更换阿里源